
认识多线程
一、进程与线程
进程:进程是程序的一次执行实例,拥有独立的内存空间和系统资源
线程:线程是进程中的一个执行单元,一个进程中可以并发多个线程,每条线程并行执行不同的任务,同一进程的多个线程共享进程的内存和资源
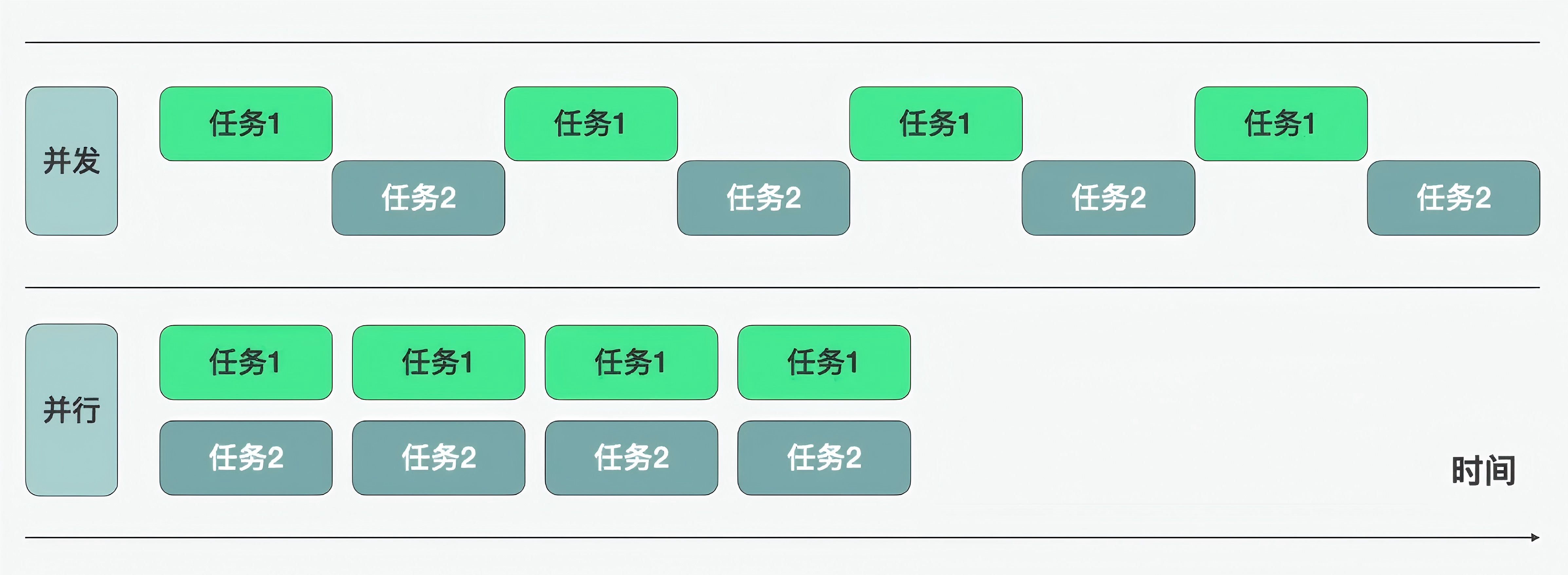
二、并发与并行
- 并行:同一时间内同时执行多个任务,需要多核cpu支持
- 并发:同一时间内处理多个任务,但是是快速切换交替执行,达到"看似同时执行"的效果,单核/多核cpu都可
三、为什么要用多线程
多线程可以充分利用CPU的硬件性能,从而提高程序的执行效率
能够更轻量地(比起多进程)实现高并发的I/O操作,如大量网络请求等
适用于需要程序响应及时的场景,如图形化界面,可以增强用户体验
Java多线程的基础实现
一、继承Thread类
class MyThread extends Thread {
@Override
public void run() {
System.out.println("线程运行中: " + Thread.currentThread().getName());
}
}
public class Main {
public static void main(String[] args) {
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
t1.start(); // 调用start方法启动线程,不要直接调用run方法
t2.start();
}
}
二、实现Runnable接口
实现Runnable接口的方式,方法为void,不能有返回值,异常需要内部try-catch
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("线程运行中: " + Thread.currentThread().getName());
}
}
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread(new MyRunnable());
Thread t2 = new Thread(new MyRunnable());
t1.start();
t2.start();
}
}
三、实现Callable接口
实现Callable接口通常需要结合FutureTask,方法可以有返回值,异常可以内部try-catch,也可以抛出
class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("线程运行中:" + Thread.currentThread().getName());
return "执行完成";
}
}
public class Main {
public static void main(String[] args) throws Exception {
MyCallable callable = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread thread = new Thread(futureTask);
thread.start();
}
}
基础多线程的局限性
- 线程完成任务后无法复用,需反复创建和销毁(资源开销大)
- 线程数量无限制,当网络请求过多时,会创建过多的线程,导致内存占用过多而产生OOM
- 功能单一,不支持异步回调、任务组合等功能
线程池
一、基本概念
线程池也是多线程的一种实现方式,它是一种基于池化思想管理线程的工具,通过预先创建一定数量的线程并复用它们来执行多个任务。线程池可以有效地解决基本多线程的痛点,减少线程创建和销毁的开销,提高系统性能和响应速度
二、适用场景
- 高并发的网络请求处理,比如商城秒杀,高铁抢票等,大量短期任务,且要求低延迟响应
- 批量数据处理,如批量计算、文件处理等,数据可以分片处理,任务可以并行
- 异步任务处理,如下订单后的短信推送,任务允许延迟执行,不阻塞主业务
ThreadPoolExecutor
ThreadPoolExecutor是Java线程池中比较常见的一种实现,是Executor框架最核心的类,所有预定义的线程池(如 FixedThreadPool、CachedThreadPool)实际都是通过配置ThreadPoolExecutor的参数实现的,ThreadPoolExecutor也可以称为自定义线程池
一、构造函数与参数详解
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 非核心线程空闲存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)
corePoolSize
核心线程数,即使线程空闲也不会被jvm回收
maximumPoolSize
线程池允许的最大线程数,当线程数池的任务队列满了之后,可以创建的最大线程数
keepAliveTime
非核心线程空闲时的存活时间,超时后会被回收
unit
空闲线程存活时间的单位
workQueue
存放待执行任务的阻塞队列。这是一个线程安全的队列,在操作元素时它会提供一种阻塞等待机制,以下是这个队列的实现:
- LinkedBlockingQueue:无界队列,底层实现是一个链表,默认容量为Integer.MAX_VALUE,任务会无限堆积,可能导致 OOM
- ArrayBlockingQueue:有界队列,底层实现是一个数组,需指定固定容量,任务会无限堆积,任务满时触发拒绝策略
- SynchronousQueue:不存储任务,直接将任务交给线程,原理是每当插入任务时,必须等到另一个线程移除任务
- PriorityBlockingQueue:支持任务优先级排序的无界队列
- DelayedWorkQueue:无界队列,也会存在OOM的风险,底层实现是一个小顶堆,可以根据任务的到期时间排序,保证队首任务是最早需要执行的。该队列是预定义线程池ScheduledThreadPoolExecutor 的专用队列,ThreadPoolExecutor无法直接配置该队列(会抛出异常)
threadFactory
线程工厂,用于自定义线程的创建过程,如设置线程名称、优先级以及线程类型(用户线程/守护线程)等
handler
拒绝策略,当workQueue已满且线程数达到maximumPoolSize时,执行的策略,有以下4种策略:
- AbortPolicy(默认):直接抛出异常(RejectedExecutionException)
- CallerRunsPolicy:由当前调用的线程直接执行该任务
- DiscardPolicy:忽略并抛弃当前任务
- DiscardOldestPolicy:丢弃队列中最旧的任务,然后执行当前任务
二、预定义线程池
预定义线程池,本质上是 ThreadPoolExecutor 的特定参数配置
FixedThreadPool(固定线程数线程池)
- 实例化:
ExecutorService executor = Executors.newFixedThreadPool(n);底层实现:

配置参数:
- 核心线程数(corePoolSize)=最大线程数(maximumPoolSize)=n(固定线程数)
- 使用无界队列LinkedBlockingQueue
- 无存活时间(线程永久保留)
特点:
- 严格限制并发线程数,适用于负载稳定的场景
- 无界队列可能导致OOM
适用场景:Web 服务器处理请求、CPU 密集型任务
CachedThreadPool(缓存线程池)
- 实例化:
ExecutorService executor = Executors.newCachedThreadPool();底层实现:

配置参数:
- 核心线程数 = 0,最大线程数 = Integer.MAX_VALUE
- 使用直接传递队列SynchronousQueue
- 线程空闲存活时间 = 60秒
特点:
- 线程数量动态伸缩,适合大量短期异步任务
- 极端情况下可能创建巨量线程(如任务持续提交),导致资源耗尽
适合场景:快速处理短时的高并发请求,但需严格监控线程数
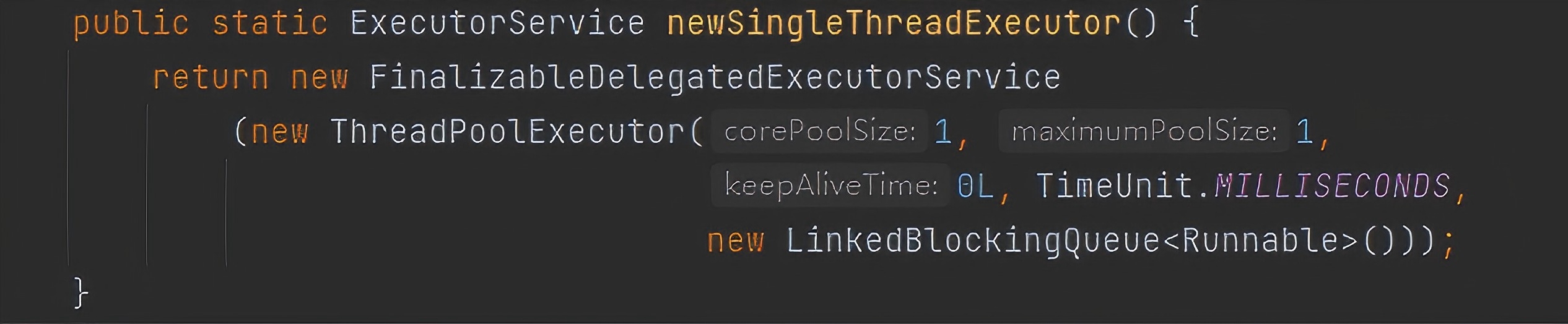
SingleThreadExecutor(单线程数线程池)
- 实例化:
ExecutorService executor = Executors.newSingleThreadExecutor();底层实现:
配置参数:
- 核心线程数 = 最大线程数 = 1
- 使用无界队列 LinkedBlockingQueue
- 无存活时间(唯一线程永久保留)
特点:
- 保证任务顺序执行,避免并发问题
- 无界队列可能导致内存溢出(OOM)
适用场景:日志顺序写入、单线程任务队列
ScheduledThreadPool(定时任务线程池)
- 实例化:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(n);底层实现:

配置参数:
- 核心线程数 = n,最大线程数 = Integer.MAX_VALUE
- 使用延迟队列 DelayedWorkQueue
- 存活时间 = 0(核心线程永久保留)
特点:
支持定时、周期性和延迟任务
非核心线程空闲时立即回收
适用场景:定时数据同步、心跳检测
三、ThreadPoolExecutor的参数配置建议
CPU 密集型任务(如计算)
- 线程数 ≈ CPU 核数(防止过多线程导致上下文切换开销)
- corePoolSize = maximumPoolSize = CPU 核数
I/O 密集型任务(如网络请求、数据库读写)
线程数 ≈ 2 * CPU 核数(利用线程等待 I/O 的空闲时间处理其他任务)
maximumPoolSize = 2 * corePoolSize = 4 * CPU 核数
四、使用示例
//创建
ExecutorService executor = new ThreadPoolExecutor(
4,
8,
60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>()
);
//调用
executor.submit(() -> System.out.println("业务逻辑代码"));
ForkJoinPool
一、需求背景
传统线程池ThreadPoolExecutor在管理大量小任务时,存在任务调度开销大、线程竞争资源等问题。因为它的任务队列是单一共享队列,对于可以分解、存在父子依赖关系的任务,则需要手动进行拆分,要把拆分完的任务和它们的父任务都存储进这个共享队列里。若此时某一个线程拿到的是一个父级任务,如果这个时候它的子任务没有完成,则需要完成这个任务的子任务才能执行,造成了线程等待,如果这个再遇到一种情况,比如在有限的线程数量的情况下,所有父、子任务的数量加起来有1000万个,但构建的时候给定的最大线程数才200万个,如果这个时候这200万个线程拿到的都是父级任务,此时这个就会整个线程池无法完成,所以这1000万个父子任务,理论上也要创建1000万个线程,但这又会导致创建大量线程而占用大量内存。所以由于ThreadPoolExecutor的特性导致了它对于可分解的任务不能高效的处理
二、简介
ForkJoinPool的设计核心是分治算法以及工作窃取,通过分治算法将一个大任务拆分成多个小任务(fork),然后从最底层的小任务开始计算,往上一层一层地合并结果(join),然后再结合工作窃取算法提高高并发性能
分治算法:分治算法属于算法思想的一种,将问题拆分为多个独立子问题,分别求解后再合并结果。例如快速排序就是分治算法的一种实现
工作窃取:
- 双端队列deque:一种头部和尾部任何一端都可以进行插入、删除、获取的队列,顺序既支持fifo也支持lifo
- 每个线程都自己维护一个deque,优先处理自己队列里头部的任务
- 如果某一个线程自己的任务队列处理完了,是空闲状态,会从其他线程的任务队列的尾部窃取任务,如果这个时候这个被窃取的队列只剩最后一个任务,会通过CAS解决原线程和窃取线程的竞争问题,以达到减少竞争、提高 CPU 利用率的目的
三、与ThreadPoolExecutor对比
任务队列模型的差异:
- ThreadPoolExecutor使用的是单一共享队列,所有任务从同一队列中获取任务
- 每个线程维护自己的本地队列Deque,空闲的线程会从其他队列窃取任务
适用场景的差异:
- ThreadPoolExecutor适合独立、无依赖的任务,如http网络请求
- ForkJoinPool更适合有父子依赖、可递归拆分的任务,如树遍历、数值计算等计算密集型的场景
四、并行流
- 简介
java8引入了stream流用以高效地处理集合数据,日常开发中通常是用stream流对集合进行链式操作实现过滤、排序、更换集合类型等。stream流又衍生出了串行流和并行流两种执行模式,串行流是单线程顺序执行,并行流则是多线程并行执行。并行流底层采用了ForkJoinPool对任务实现拆分和合并
- 串行流与并行流对比
- 串行流的执行方式是单线程顺序执行;并行流的是多线程并行处理,任务自动拆分
- 集合的数据量少时适合使用串行流,数据量较大时则建议采用并行流
- 并行流使用时需注意共享资源的线程安全问题
五、使用示例
继承RecursiveAction:用于执行不返回结果的并行任务,直接修改传入的数据结构;需要重写compute(),然后定义任务的拆分和执行逻辑
示例:并行更新数组中的元素,将数组中的每个元素乘以 2
public class ArrayProcessor extends RecursiveAction {
private final int[] array;
private final int start;
private final int end;
private static int THRESHOLD = 1000; //最大计算数
public ArrayProcessor(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if(end - start <= THRESHOLD) {
//直接处理小任务
for(int i = start; i < end; i++) {
array[i] = array[i] * 2; //将元素*2
}
}else {
// 拆分任务
int mid = (start + end) / 2;
ArrayProcessor left = new ArrayProcessor(array, start, mid);
ArrayProcessor right = new ArrayProcessor(array, mid, end);
invokeAll(left, right); // 并行执行子任务
}
}
public static void main(String[] args) {
int[] data = new int[10000];
ForkJoinPool pool = new ForkJoinPool();
ArrayProcessor task = new ArrayProcessor(data, 0, data.length);
pool.invoke(task); // 执行任务
}
}
继承RecursiveTask:用于执行返回结果的并行任务,通过 join() 获取子任务结果,合并后返回最终值;需重写 compute(),返回计算结果
示例:计算斐波那契数列
public class FibonacciTask extends RecursiveTask<Integer> {
private final int n;
public FibonacciTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if(n <= 1) {
return n;
}else {
//拆分任务
FibonacciTask f1 = new FibonacciTask(n - 1);
FibonacciTask f2 = new FibonacciTask(n - 2);
f1.fork(); // 异步执行子任务
return f2.compute() + f1.join(); // 合并结果
}
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
FibonacciTask task = new FibonacciTask(10);
System.out.println(pool.invoke(task)); // 输出:55
}
}
- 并行流
- 示例:并行更新数组中的元素
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
ForkJoinPool customPool = new ForkJoinPool(4);
customPool.submit(() ->
list.parallelStream()
.mapToLong(x -> x * x)
.sum()
).join();